



导语
“满城尽谈大数据”,但很多人其实并不理解大数据真正价值是什么,哈佛大学Gary King教授用3个大数据研究案例告诉你:有数据固然好,但是如果没有分析,数据的价值就没法体现。
2017年初,哈佛大学政治学系教授加里·金(Gary King)在上海交通大学举办了一场名为《大数据,重要的不是数据》(Big Data is Not About the Data)的讲座。
DT君先来介绍一下主讲人:Gary King是哈佛大学的校级教授(University Professor)。King教授以实证研究知名,擅长量化研究,其研究涉及政治学、公共政策、法学、心理学和统计学等领域。

(图片说明:1月4日,Gary King教授在上海交大演讲现场)
以下是Gary King 教授演讲实录(有删节):
我工作的领域叫做量化社会科学(Quantitative Social Science),有时,它有一个别称,叫大数据。“大数据”这个词最早是媒体发现的,它试图向大众解释我们是做什么的,目前看来解释的效果还不错。
然而,大数据的价值不是在数据本身,虽然我们需要数据,数据很多时候只是伴随科技进步而产生的免费的副产品。比如说,学校为了让学生能更高效地注册而引进了注册系统,因而有了学生的很多信息,这些都是因为技术改进而产生的数据增量。
大数据的真正价值在于数据分析。数据是为了某种目的存在,目的可以变,我们可以通过数据来了解完全不同的东西……有数据固然好,但是如果没有分析,数据的价值就没法体现。
先来看一个大数据在公共政策层面运用的案例。
我们曾经做过一个评估研究,发现2000年以后美国社会保障管理总署(U.S. Social Security Administration,简称“SSA”)对于美国社保账户及人口寿命的预测有系统性偏差。
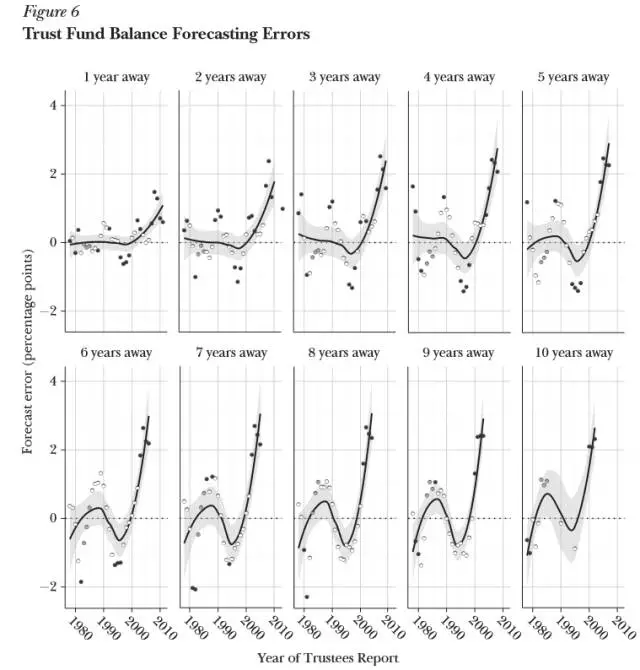
(图片说明:2000年以后SSA对社保基金账户情况的预测出现显著偏差;来源:Gary King论文)
大背景是,美国的社会保障平台是美国最大的单一政府平台,它的资金是跨代流动的——当前退休者的养老金供给来自于他们的下一代,即现在工作的人交的税金。
所以SSA需要预测这个信托基金项目里的资金流,以及人的寿命,正确预测这两点很重要,如果人们比SSA预期的更长寿——虽然这是好事——就很可能导致信托基金里就没有足够的钱给他们养老了。
我们研究发现,SSA的预测在2000年以后出现了系统性偏差——发生偏差的原因之一,是SSA使用的模型本质上定性分析的模型,且多年来几乎没有调整。由于一些药物的使用和癌症早期发现,美国人开始比模型预测地更长寿了。
我们通过分析得出的结论是,美国社保信托基金至少存在8千亿美元的缺口。
虽然结论有点不幸,但是政府需要提前知道。这样政府就可以有空间在税率,退休年龄等方面进行调整。这是公共政策层面的话题。
关于定性分析和定量分析,其实不是泾渭分明的。做分析全靠定性分析(由人主导)是不够的,因为你有很多数据不知道该怎么处理。 全靠定量分析(由机器主导)也不行,这就像一张巨大的excel表,但是表中没有行、列的标签。所以,大数据分析需要的是由人主导,由计算机辅助的技术(we need computer-assisted, human-led technology)。
我们还做过一个计算机辅助阅读的实验。我们开发了一套计算机辅助、自动化阅读的技术,这项技术能帮助人们从非结构化的文字中提取、组织并且处理大量信息。
我们曾用该技术处理了64000篇国会议员官方发布的新闻稿,想通过这项基础帮我们作分类,看国会议员在新闻稿中都说了些什么。
结果我们发现,居然有高达27%的议员发布的新闻稿内容只是单纯地想抨击对方(Partisan Taunting),而不是想要平衡预算或停止战争,或解决问题。

(图片说明:Gary King表示,抨击对方政党从个人角度来看是理性的,但是从整个集群的角度来看,是非理性的,如果抨击对方的言语增多,政党之间的合作关系和能效会减弱;来源:Gary King研究成果单页)
大数据时代,我们可以通过去量化过去不能量化的信息,使用精妙的统计学方法分析这些信息成为可能。
现在,我们都可以对一些强定性属性(inherently qualitative)的东西作定量分析了,如音频和视频。但是,目前仍有一些定性分析工作者要分析的内容还未被量化。所以,定性分析、定量分析要配合操作才行。
我参与过一个产品项目叫做Perusall。“Peruse”是仔细精读的意思,Perusall就是peruse + all,可以简单理解为大家一起读。
这个产品产生的背景是,大学教授会给同学布置阅读作业,但是教授很难评估学生是否阅读了规定的章节。如果有的学生没读而有的学生读了,这对整体课堂的授课效果会有影响。
Perusall的好处之一,是它把阅读从一个个体活动变成了一个集体活动。阅读文章的同学可以对自己看不懂的部分做批注,也可以对其他同学的批注作回复解答。这样更容易调动同学阅读的主动积极性,让阅读变得更有趣。人天生是社会动物,这也是为什么人们相比于在iTunes里听歌更愿意花钱去看演唱会,虽然前者音乐声音更清晰。
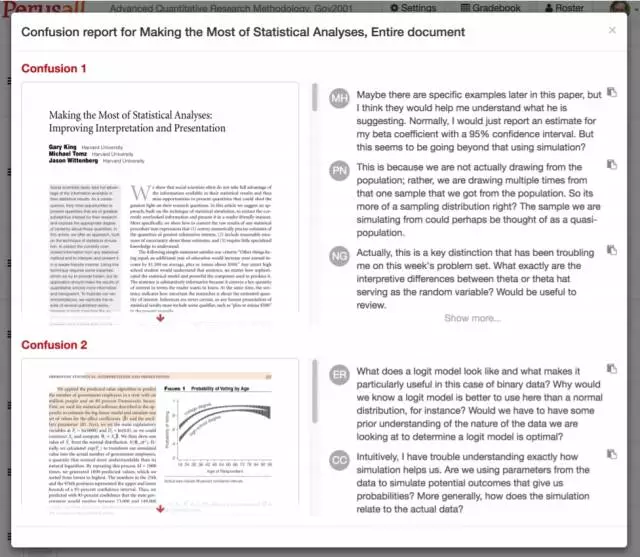
(图片说明:“学生困惑报告”样本;来源:哈佛官网)
一旦学生用Perusall在线上阅读之后,我们就有了很多之前不可能互获取的数据:知道学生在读什么,他们对阅读内容的反馈怎样,他们在读每一页的时候花多少时间;当然,如果你没有读书的第46-47页,我们也会知道这个。
一方面,Perusall会基于每个学生的阅读情况和评价质量,对学生的这项阅读作业进行打分,从老师的层面看,这省去了原先阅读作业不易评估的问题。
另一方面,Perusall会分析这些阅读数据,知道学生们读到哪里时觉得困惑。
Perusall可以在老师上课前生成一个“学生困惑报告”(Students confusion report)。拿到这份报告,我就可以在一走进课堂时说,“根据你们的阅读情况,你们可能有以下三个问题。”
注:本文根据Gary King教授2017年1月4日在上海交通大学的讲座内容整理、编辑而成
编辑|张弦:zhangxian@yicai.com
联系我们 Contact us
微信公众号:qingchuang999
公司网站:www.qingchuang999.com
电子邮箱:jiangdr@qingchuang999.com
项目联系:13641035449 蒋经理
工商注册:18612441034 徐经理
办公入驻:13911538335 徐总监
会议场地:15010672595 邵经理
联系地址:北京市海淀区大钟寺13号院华杰大厦负一层清创空间